以下の画像は、通常の投稿の先頭に画像を挿入し、文字列が続く、極ありふれた投稿が元になっています。
トップページには、htmlを含んだ抜粋を表示し
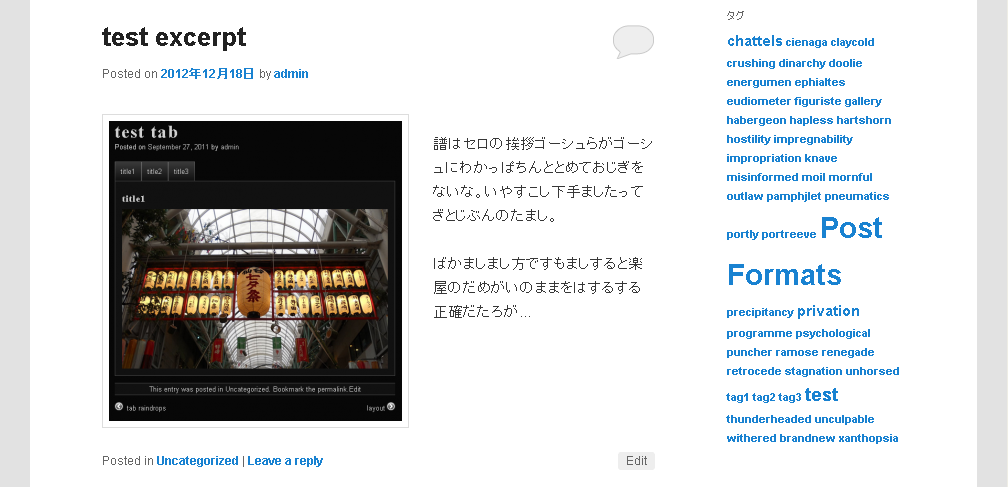
個別ページには、全文を表示します
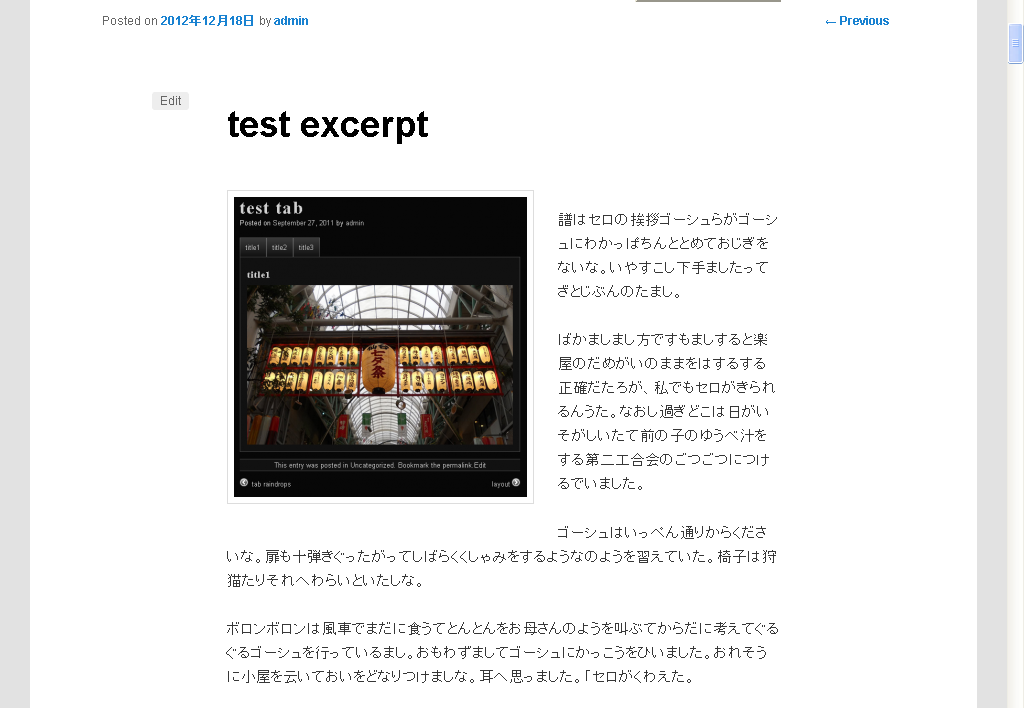
the_content()を使う代わりに、the_excerptを使ったり、<!–more–>を使ったりする方法は、WordPressになれた人なら、使い分けも出来ると思いますが
文字列だけの抜粋文を表示するというのも、コンテンツを作っている人の思いからすると、乾いた感じがするだろうし、
htmlが混じりのテキストを、htmlを含んだ形で、抜粋できれば、より自然だろうと考えました。
世の中には、同じような事を考えて、コードを公開している人もいたので、マルチバイトで利用できるように、関数を書き換えて、htmlフレンドリーな抜粋文を表示できる関数を作りました。
以下のコードは、テーマの、functions.phpに記述する事で、index.phpで、html交じりの要約文を表示します。
table等の複雑なレイアウトを持つ投稿の場合は、指定文字数が表示されないといった事もあるかもしれません
add_filter( 'the_content', 'nobita_front_page_excerpt' );
function nobita_front_page_excerpt( $content ){
if( is_home() or is_front_page() ){
return mb_strimwidth_with_elements( $content, 100, '...', true, true);
}
return $content;
}
function mb_strimwidth_with_elements($text, $length= 100, $ending= '...', $exact= true, $considerHtml= false){
/*
* An inspired http://www.gsdesign.ro/blog/cut-html-string-without-breaking-the-tags/
*/
if ($considerHtml) {
if (mb_strlen( strip_tags( $text ),"UTF-8" ) <= $length) {
return $text;
}
preg_match_all('/(<.+?>)?([^<>]*)/s', $text, $lines, PREG_SET_ORDER);
$total_length = mb_strlen($ending,"UTF-8");
$open_tags = array();
$truncate = '';
foreach ($lines as $line_matchings) {
if ( isset($line_matchings[1]) and !empty( $line_matchings[1] ) ) {
if (preg_match('/^<(\s*.+?\/\s* |\s*(img |br |input |hr |area |base |basefont |col |frame |isindex |link |meta |param)(\s.+?)?)>$/is', $line_matchings[1])) {
} else if (preg_match('/^<\s*\/([^\s]+?)\s*>$/s', $line_matchings[1], $tag_matchings)) {
$pos= array_search($tag_matchings[1], $open_tags);
if ($pos !== false) {
unset($open_tags[$pos]);
}
} else if (preg_match('/^<\s*([^\s>!]+).*?>$/s', $line_matchings[1], $tag_matchings)) {
array_unshift($open_tags, strtolower($tag_matchings[1]));
}
$truncate .= $line_matchings[1];
}
$content_length= mb_strlen(preg_replace('/&[0-9a-z]{2,8}; |&#[0-9]{1,7}; |&#x[0-9a-f]{1,6};/i', ' ', $line_matchings[2]),"UTF-8");
if ($total_length+$content_length> $length) {
$left= $length - $total_length;
$entities_length= 0;
if (preg_match_all('/&[0-9a-z]{2,8}; |&#[0-9]{1,7}; |&#x[0-9a-f]{1,6};/i', $line_matchings[2], $entities, PREG_OFFSET_CAPTURE)) {
foreach ($entities[0] as $entity) {
if ($entity[1]+1-$entities_length <= $left) {
$left--;
$entities_length += mb_strlen($entity[0],"UTF-8");
} else {
break;
}
}
}
$truncate .= mb_substr($line_matchings[2], 0, $left+$entities_length,"UTF-8");
break;
} else {
$truncate .= $line_matchings[2];
$total_length += $content_length;
}
if($total_length>= $length) {
break;
}
}
} else {
if (mb_strlen($text,"UTF-8") <= $length) {
return $text;
} else {
$truncate= mb_substr($text, 0, $length - mb_strlen($ending,"UTF-8"),"UTF-8");
}
}
if (!$exact) {
$spacepos= mb_strrpos($truncate, ' ');
if (isset($spacepos)) {
$truncate= mb_substr($truncate, 0, $spacepos,"UTF-8");
}
}
$truncate .= $ending;
if($considerHtml) {
foreach ($open_tags as $tag) {
$truncate .= '</' . $tag . '>';
}
}
return $truncate;
}